Extremely large, sparse graphs with billions of nodes and hundreds of billions of edges arise in many important problem domains ranging from social science, bioinformatics, to video content analysis and search engines. In response to the increasingly larger and more diverse graphs, and the critical need of analyzing them, we focus on large scale graph analytics, an essential class of big data analysis, to explore the comprehensive relationship among a vast collection of interconnected entities. However, it is challenging for existing computer systems to process the massive-scale real-world graphs, not only due to their large memory footprint, but also that most graph algorithms entail irregular memory access patterns and a low compute-to-memory access ratio.
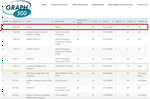
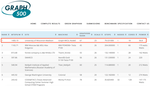
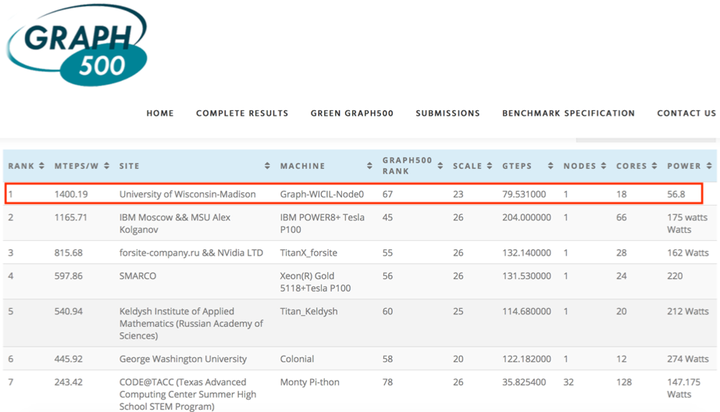
In this research, we invented “degree-aware” hardware/software techniques to improve graph processing efficiency. Our research is built atop a key insight that we obtained from architecture-independent algorithm analysis, which has not been revealed in prior work. More specifically, we identified that a key challenge in processing massive-scale graphs is the redundant graph computations caused by the presence of high-degree vertices which not only increase the total amount of computations but also incur unnecessary random data access. To address this challenge, we developed variants of graph processing systems on an FPGA-HMC platform [Zhang2018FPGA-Graph, Khoram2018FPGA, Zhang2017FPGA-BFS]. For the first time, we leverage the inherent graph property i.e. vertex degree to co-optimize algorithm and hardware architecture. In particular, the unique contributions we made include two algorithm optimization techniques: degree-aware adjacency list reordering and degree-aware vertex index sorting. The former reduces the number of redundant graph computations, while the latter creates a strong correlation between vertex index and data access frequency, which can be effectively applied to guide the hardware design. Further, by leveraging the strong correlation between vertex index and data access frequency created by degree-aware vertex index sorting, we developed two platform-dependent hardware optimization techniques, namely degree-aware data placement and degree-aware adjacency list compression. These two techniques together substantially reduce the amount of external memory access. Finally, we completed the full system design on an FPGA-HMC platform to verify the effectiveness of these techniques. Our implementation achieved the highest performance (45.8 billion traversed edges per second) among existing FPGA-based graph processing systems and was ranked No. 1 on GreenGraph500 list.
 Green Graph500 (updated June 19, 2019)
Green Graph500 (updated June 19, 2019)