Research
At PennCIL, our research focuses on future systems in two general directions: 1) Augmenting computer systems with domain specific accelerators and emerging memories, an essential step towards next-generation systems. It requires modest system changes and has low deployment barrier but the performance gain might be potentially limited. 2) Rethinking computer systems with post-CMOS technology, a more aggressive approach in pushing innovations across the entire system stack. It could lead to dramatic improvement in performance but often requires more disruptive change in both hardware and software.

Augmenting Computer Systems with Domain Specific Accelerators/Emerging Memories
In this research theme, we organize our research around three high-level questions: 1) How to design domain specific accelerators for big data and machine learning applications? 2) What kind of system abstractions are needed to convert hardware specialization into direct benefits that can actually be realized by end-applications and “everyday” programmers? 3) How to effectively evaluate these cross-stack system methods with high fidelity, fairness, and performance? In this research, we aim to answer these questions via the following three paths: 1) architecture/algorithm co-design, 2) mechanisms and abstractions for virtualization, and 3) open-source system research infrastructure.
ARCHITECTURE/ALGORITHM CO-DESIGN
Large Scale Graph Analytics
Extremely large, sparse graphs with billions of nodes and hundreds of billions of edges arise in many important problem domains ranging from social science, bioinformatics, to video content analysis and search engines. In response to the increasingly larger and more diverse graphs, and the critical need of analyzing them, we focus on large scale graph analytics, an essential class of big data analysis, to explore the comprehensive relationship among a vast collection of interconnected entities. However, it is challenging for existing computer systems to process the massive-scale real-world graphs, not only due to their large memory footprint, but also that most graph algorithms entail irregular memory access patterns and a low compute-to-memory access ratio.
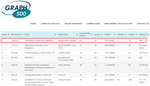
In this research, we invented “degree-aware” hardware/software techniques to improve graph processing efficiency. Our research is built atop a key insight that we obtained from architecture-independent algorithm analysis, which has not been revealed in prior work. More specifically, we identified that a key challenge in processing massive-scale graphs is the redundant graph computations caused by the presence of high-degree vertices which not only increase the total amount of computations but also incur unnecessary random data access. To address this challenge, we developed variants of graph processing systems on an FPGA-HMC platform [Zhang2018FPGA-Graph, Khoram2018FPGA, Zhang2017FPGA-BFS]. For the first time, we leverage the inherent graph property i.e. vertex degree to co-optimize algorithm and hardware architecture. In particular, the unique contributions we made include two algorithm optimization techniques: degree-aware adjacency list reordering and degree-aware vertex index sorting. The former reduces the number of redundant graph computations, while the latter creates a strong correlation between vertex index and data access frequency, which can be effectively applied to guide the hardware design. Further, by leveraging the strong correlation between vertex index and data access frequency created by degree-aware vertex index sorting, we developed two platform-dependent hardware optimization techniques, namely degree-aware data placement and degree-aware adjacency list compression. These two techniques together substantially reduce the amount of external memory access. Finally, we completed the full system design on an FPGA-HMC platform to verify the effectiveness of these techniques. Our implementation achieved the highest performance (45.8 billion traversed edges per second) among existing FPGA-based graph processing systems and was ranked No. 1 on GreenGraph500 list.
We have broken our previous record that we made at UW-madison in 2019 and created a new world record at Penn!
 Green Graph500: New ENIAD ranking (updated June 30, 2021)
Green Graph500: New ENIAD ranking (updated June 30, 2021)
 Green Graph500: Old ranking (updated June 19, 2019)
Green Graph500: Old ranking (updated June 19, 2019)
More news can be found at Penn Today, Penn Engineering Today and TCFPGA News.
Deep Leaning and AI
Deep neural networks (DNNs) deliver impressive results for a variety of challenging tasks in computer vision, speech recognition, and natural language processing, at the cost of higher computational complexity and larger model size. To reduce the load of taxing DNN infrastructures, a number of FPGA-based DNN accelerators have been proposed via new micro-architectures, data ow optimizations, or algorithmic transformation. Due to the extremely large design space, it is challenging to attain good insights on how to design optimal accelerators on a target FPGA.
In this research, we take an alternative, and more principled approach to guide accelerator architecture design and optimization. We borrow the insights from the roofline model and further improve it by taking both on-chip and off-chip memory bandwidth into consideration. We apply the model to quantify the difference between available resources provided by native hardware (FPGA devices) and actual resources demanded by the application (CNN classification kernel). To tackle the problem, we develop a number of hardware/software techniques and implement them on FPGA [Zhang2017FPGA-CNN]. The demonstrated accelerator was recognized as the highest performance and the most energy efficient accelerator for dense convolutional neural network (CNN) compared to the state-of-the-art FPGA-based designs.
MECHANISMS AND ABSTRACTIONS FOR VIRTUALIZATION IN CLOUD
While traditionally being used in embedded systems, custom silicon (e.g., FPGAs) has recently begun to make their way into data centers and the cloud (Amazon AWS EC2 F1 instances, Microsoft Brainwave, Google TPU etc.). While these programmable data-flow architectures provide the lucrative benefits of fine-grained parallelism and high flexibility to accelerate a wide spectrum of applications, system support for them in the context of multi-tenant cloud environment, however, is in its infancy and has two major limitations, 1) inefficient resource management due to the tight coupling between compilation and runtime management, and 2) high programming complexity when exploiting scale-out acceleration, for which the root cause is that hardware resources are not virtualized.
In this research, we take FPGA as a case study and develop a full stack solution that can address these limitations and thus, enable virtualization of FPGA clusters in multi-tenant cloud computing environment. Specifically, the key contribution is a new system abstraction that can effectively decouple the compilation and runtime resource management. It allows applications to be compiled offline onto the proposed abstraction and resource allocation to be dynamically determined at runtime. Moreover, it creates an illusion of a single/large virtual FPGA to users, thereby reducing the programming complexity and supporting scale-out acceleration. It also provides virtualization support for the peripheral components (e.g. on-board DRAM, Ethernet), as well as protection and isolation support to ensure a secure execution in multi-tenant cloud environment [Zha2020ASPLOS].
OPEN SOURCE COMPUTER SYSTEM INFRASTRUCTURE
Hardware-software co-design studies targeting next-generation computer systems that are equipped with emerging memories (HBM/HMC, NVM, etc.) are fundamentally hampered by a lack of scalable, performant and accurate simulation platform. Using software simulator is fundamentally bottlenecked by the low simulation speed and low fidelity, making it impractical to run realistic software stack. Such a challenge has limited effective cross-stack innovations (across computer architecture, OS, compiler, machine learning, and domain sciences). Past efforts have largely focused on simulation infrastructure for processor cores with highly simplified models of the memory subsystem. As a key contribution to the community (including SRC JUMP centers, broad academia and industry) to better drive cross-stack memory system research, we have been developing MEG [Zhang2019FCCM] – an open source FPGA- based simulation platform that enables cycle-exact micro-architecture simulation for computer systems with a special focus on memory subsystem (heterogeneous memory, near/in-memory acceleration). In MEG, we combine silicon- proven RTL design of RISC-V cores with configurable heterogeneous memory subsystems (HMC/HBM/NVM). It is capable of running realistic software stacks including booting Linux and comprehensive application software with high fidelity (cycle-exact microarchitectural models derived from synthesizable RTL), flexibility (modifiable to include custom RTL user IP and/or more abstract models), reproducibility, observability, target software support and performance. MEG can be an effective complement to previous RAMP and more recent Firesim projects in covering memory space and a contribution to the open source RISC-V community.

Rethinking Computer Systems with Post-CMOS Technology
Looking forward, we believe more disruptive approaches are needed to fundamentally re-think about how we build computers to address von Neumann bottleneck. We envision future computer chips will not solely be made by Si but rather can utilize and optimize the best of various post-CMOS technologies (including but not limited to novel 1D/2D devices, spintronics, resistive switching devices, quantum electrical/optical device, etc.), to effectively complement silicon CMOS in providing auxiliary/ancillary functions (or cost benefits) that otherwise cannot be easily achieved with silicon CMOS. In this research, we take emerging nonvolatile memory technology (e.g., RRAM) as a case study to showcase two general-purpose in-memory computing architectures based on two radically different non-von Neumann machine models. Note that these two architectures are fundamentally different from prior rich literature of applying memory array as domain-specific dot-product computing unit.
Liquid Silicon
Liquid Silicon (L-Si) is a general-purpose in-memory computing architecture with complete system support that addresses several key fundamental limitations of state-of-the-art reconfigurable data-flow architectures (including FPGA, TPU, CGRA, etc.) in supporting emerging machine learning and big data applications. As compared with most projects in literature which focus on part of the system stack, L-Si is a full stack solution that comprises architecture [Zha2018FPGA], compiler [Zha2016ICCAD], programming model and system integration [Zha2018ASPLOS], with a real chip demonstration [Zha2019VLSIC]. The computing model of L-Si is radically different from state-of-the-art reconfigurable data-flow architectures. It maximally reuses the memory array itself (instead of placing computation units near the array) to perform a) heavy weight computation (logic), b) light weight computation(search), c) data storage (memory), and d) communication (routing), with minimal requirement in CMOS supporting circuitry, which can thus be further placed beneath the array. Therefore, it inherits the great benefits of semiconductor memory in integration density and cost, and offers orders of magnitude more parallel data processing capability in situ in the memory array than the best-known solution today. For the first time, it fundamentally blurs the boundary between computation and storage, by exploiting a continuum of general-purpose in-memory compute capabilities across the whole spectrum, from full memory to full computation, or intermediate states in between (partial memory and partial computation). Thus, it provides programmers (or compiler) more flexibility to customize hardware’s compute and memory resources to better match applications needs for higher performance and energy efficiency. We leverage such unique property and provide compiler support to facilitate the programming of applications written in high-level programming languages (e.g. OpenCL) and frameworks (e.g. TensorFlow, MapReduce) while fully exploiting the unique architectural capability of L-Si. We also provide scalable multi-context architectural support to minimize reconfiguration overhead for assisting virtualization when combined with our system stack.
 Timeline of L-Si project
Timeline of L-Si project
To prove the feasibility of L-Si, we fabricated a test chip in 130 nm CMOS process with HfO2 RRAM – the first real-chip demonstration for general purpose in-memory computing using RRAM.
 Die Photo and Chip Characteristics of L-Si
Die Photo and Chip Characteristics of L-Si
With proposed system support, we evaluated a broad class of legacy and emerging machine learning workloads. Our measurement confirmed the chip operates reliably at low voltage of 650 mV when running these workloads. It achieves 60.9 TOPS/W in performing neural network inferences and 480 GOPS/W in performing high-dimensional similarity search (a key big data application) at nominal voltage supply of 1.2V, showing > 3x and ~100x power efficiency improvement over the state-of-the-art domain-specific CMOS-/RRAM-based accelerators without sacrificing the programmability. In addition, it outperforms the latest nonvolatile FPGA in energy efficiency by > 3x in general compute-intensive applications. As L-Si is a fundamental new computing technology, moving further, we will explore how to scale it up to warehouse computers and scale it down to IoT devices by further specializing the software/hardware stacks.
 Comparing L-Si with State-of-the-Art
Comparing L-Si with State-of-the-Art
Two-Dimensional Associative Processor
The research project, titled “Associative In-Memory Graph Processing Paradigm: Towards Tera-TEPS Graph Traversal In a Box", won the NSF CAREER Award in 2018. In this research, we developed a radically new computing paradigm, namely two-dimensional associative processing (2D AP) to further advance our previous FPGA-based graph processing architectures and fundamentally address their limitations. Mathematically, 2D AP is a new general-purpose computing model that exploits an extra dimension of parallelism (both intra-word and inter-word parallelism) to accelerate computation as compared with traditional AP which only exploit inter-word parallelism. It is particularly beneficial for massive-scale graph processing. For the first time, we provide a theoretical proof that 2D AP is inherently more efficient as measured by “architecturally determined complexity” in runtime/area/energy than both von Neumann architecture and traditional AP paradigm in performing graph computation. We also provide detailed micro-architectures and circuits to best implement the proposed computing model, with domain-special language support. A preliminary published version of 2D AP [Khoram2018CAL] was recognized as best of CAL (IEEE Computer Architecture Letters) in 2018.